Connect Your Custom RAG Pipeline to a Letta Agent
You’ve built a powerful Retrieval-Augmented Generation (RAG) pipeline with its own vector database, but now you want to connect it to an intelligent agent. This guide is for developers who want to integrate their existing RAG stack with Letta, giving them full control over their data while leveraging Letta’s advanced agentic capabilities.
By the end of this tutorial, we’ll build a research assistant that uses a ChromaDB Cloud database to answer questions about scientific papers. We will explore two distinct methods for achieving this.
What You’ll Learn
Section titled “What You’ll Learn”- Standard RAG: How to manage retrieval on your client and inject context directly into the agent’s prompt. This gives you maximum control over the data the agent sees.
- Agentic RAG: How to empower your agent with a custom tool, allowing it to decide when and what to search in your vector database. This creates a more autonomous and flexible agent.
Prerequisites
Section titled “Prerequisites”To follow along, you need free accounts for the following platforms:
- Letta: To access the agent development platform
- ChromaDB Cloud: To host our vector database
You will also need Python 3.8+ and a code editor.
Getting Your API Keys
Section titled “Getting Your API Keys”We’ll need two API keys for this tutorial.
Get your Letta API Key
-
Create a Letta Account
If you don’t have one, sign up for a free account at letta.com.
-
Navigate to API Keys
Once logged in, click on API keys in the sidebar.
-
Create and Copy Your Key
Click + Create API key, give it a descriptive name, and click Confirm. Copy the key and save it somewhere safe.
Get your ChromaDB Cloud API Key
-
Create a ChromaDB Cloud Account
Sign up for a free account on the ChromaDB Cloud website.
-
Create a New Database
From your dashboard, create a new database.
-
Get Your API Key and Host
In your project settings, you will find your API Key and Host URL. We’ll need both of these for our scripts.
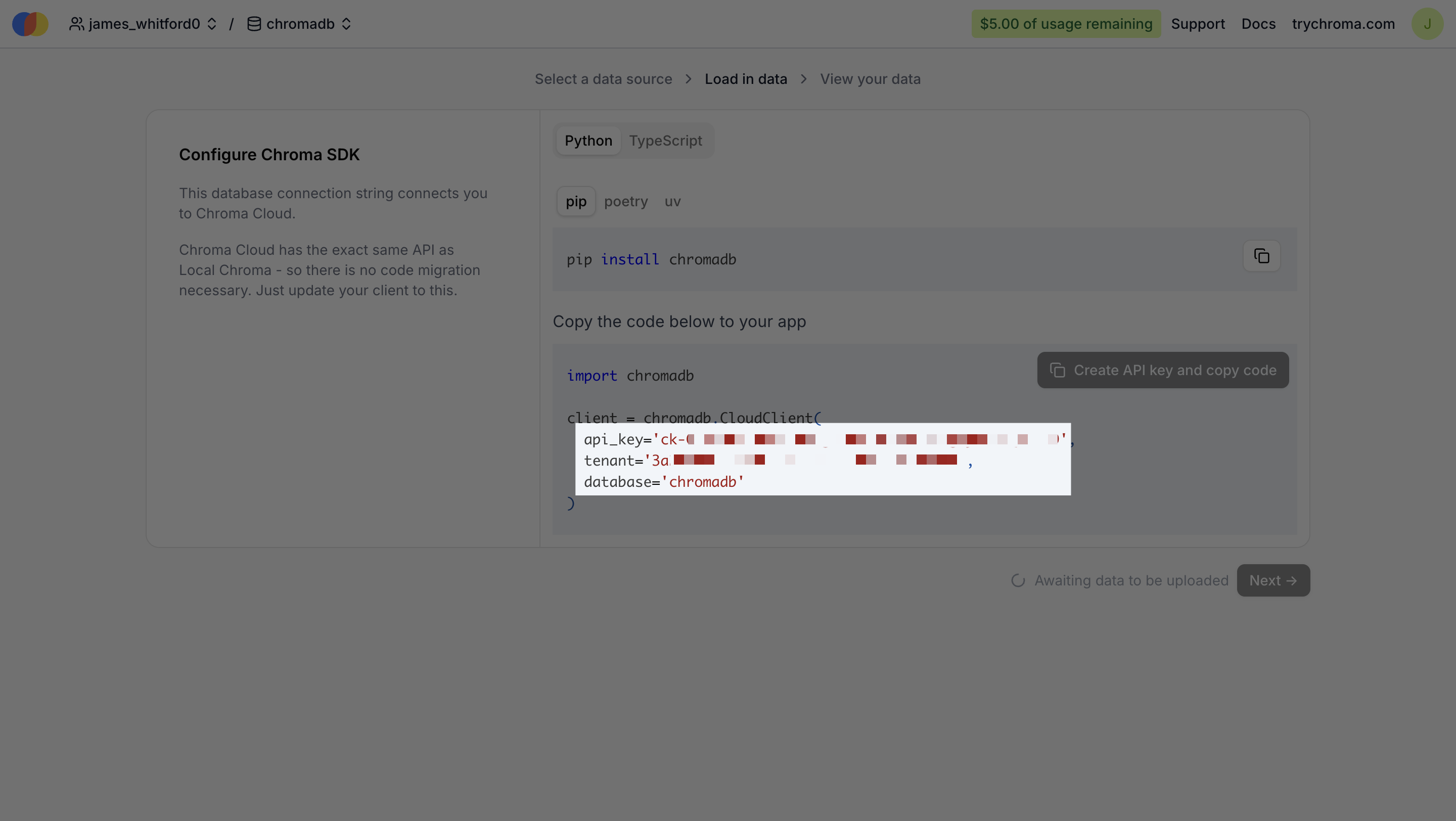
Once you have these keys, create a .env file in your project directory and add them like this:
LETTA_API_KEY="..."CHROMA_API_KEY="..."CHROMA_TENANT="..."CHROMA_DATABASE="..."Part 1: Standard RAG — Full Control on the Client-Side
Section titled “Part 1: Standard RAG — Full Control on the Client-Side”In the standard RAG approach, our application takes the lead. It fetches the relevant information from our ChromaDB database and then passes this context, along with our query, to a simple Letta agent. This method is direct, transparent, and keeps all the retrieval logic in our client application.
Step 1: Set Up the Cloud Vector Database
Section titled “Step 1: Set Up the Cloud Vector Database”First, we need to populate our ChromaDB Cloud database with the content of the research papers. We’ll use two papers for this demo: “Attention Is All You Need” and “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”.
Before we begin, let’s create a Python virtual environment to keep our dependencies isolated:
python -m venv venvsource venv/bin/activate # On Windows, use: venv\Scripts\activateDownload the research papers we’ll be using:
curl -o 1706.03762.pdf https://arxiv.org/pdf/1706.03762.pdfcurl -o 1810.04805.pdf https://arxiv.org/pdf/1810.04805.pdfNow, create a requirements.txt file with the necessary Python libraries:
letta-clientchromadbpypdfpython-dotenvInstall them using pip:
pip install -r requirements.txtNow, create a setup.py file. This script will load the PDFs, split them into manageable chunks, and ingest them into a ChromaDB collection named rag_collection.
import osimport chromadbimport pypdffrom dotenv import load_dotenv
load_dotenv()
def main(): # Connect to ChromaDB Cloud client = chromadb.CloudClient( tenant=os.getenv("CHROMA_TENANT"), database=os.getenv("CHROMA_DATABASE"), api_key=os.getenv("CHROMA_API_KEY") )
# Create or get the collection collection = client.get_or_create_collection("rag_collection")
# Ingest PDFs pdf_files = ["1706.03762.pdf", "1810.04805.pdf"] for pdf_file in pdf_files: print(f"Ingesting {pdf_file}...") reader = pypdf.PdfReader(pdf_file) for i, page in enumerate(reader.pages): collection.add( ids=[f"{pdf_file}-{i}"], documents=[page.extract_text()] )
print("\nIngestion complete!") print(f"Total documents in collection: {collection.count()}")
if __name__ == "__main__": main()Run the script from your terminal:
python setup.pyThis script connects to your ChromaDB Cloud instance, creates a collection, and adds the text content of each page from the PDFs as a separate document. Your vector database is now ready.
Step 2: Create a “Stateless” Letta Agent
Section titled “Step 2: Create a “Stateless” Letta Agent”For the standard RAG approach, the Letta agent doesn’t need any special tools or complex instructions. Its only job is to answer a question based on the context we provide. We can create this agent programmatically using the Letta SDK.
Create a file named create_agent.py:
import osfrom letta_client import Lettafrom dotenv import load_dotenv
load_dotenv()
# Initialize the Letta clientclient = Letta(token=os.getenv("LETTA_API_KEY"))
# Create the agentagent = client.agents.create( name="Stateless RAG Agent", description="This agent answers questions based on provided context. It has no tools or special memory.", memory_blocks=[ { "label": "persona", "value": "You are a helpful research assistant. Answer the user's question based *only* on the context provided." } ])
print(f"Agent '{agent.name}' created with ID: {agent.id}")Run this script once to create the agent in your Letta project.
python create_agent.py
Step 3: Query, Format, and Ask
Section titled “Step 3: Query, Format, and Ask”Now we’ll write the main script, standard_rag.py, that ties everything together. This script will:
- Take a user’s question.
- Query the
rag-democollection in ChromaDB to find the most relevant document chunks. - Construct a detailed prompt that includes both the user’s question and the retrieved context.
- Send this combined prompt to our stateless Letta agent and print the response.
import osimport chromadbfrom letta_client import Lettafrom dotenv import load_dotenv
load_dotenv()
# Initialize clientsletta_client = Letta(token=os.getenv("LETTA_API_KEY"))chroma_client = chromadb.CloudClient( tenant=os.getenv("CHROMA_TENANT"), database=os.getenv("CHROMA_DATABASE"), api_key=os.getenv("CHROMA_API_KEY"))
AGENT_ID = "your-stateless-agent-id" # Replace with your agent ID
def main(): while True: question = input("Ask a question about the research papers: ") if question.lower() in ['exit', 'quit']: break
# 1. Query ChromaDB collection = chroma_client.get_collection("rag_collection") results = collection.query(query_texts=[question], n_results=3) context = "\n".join(results["documents"][0])
# 2. Construct the prompt prompt = f'''Context from research paper:{context}Question: {question}Answer:'''
# 3. Send to Letta Agent response = letta_client.agents.messages.create( agent_id=AGENT_ID, messages=[{"role": "user", "content": prompt}] )
for message in response.messages: if message.message_type == 'assistant_message': print(f"Agent: {message.content}")
if __name__ == "__main__": main()When you run this script, your application performs the retrieval, and the Letta agent simply provides the answer based on the context it receives. This gives you full control over the data pipeline.
Part 2: Agentic RAG — Empowering Your Agent with Tools
Section titled “Part 2: Agentic RAG — Empowering Your Agent with Tools”In the agentic RAG approach, we delegate the retrieval process to the agent itself. Instead of our application deciding what to search for, we provide the agent with a custom tool that allows it to query our ChromaDB database directly. This makes the agent more autonomous and our client-side code much simpler.
Step 4: Create a Custom Search Tool
Section titled “Step 4: Create a Custom Search Tool”A Letta tool is essentially a Python function that your agent can call. We’ll create a function that searches our ChromaDB collection and returns the results. Letta handles the complexities of exposing this function to the agent securely.
Create a new file named tools.py:
import chromadbimport os
def search_research_papers(query_text: str, n_results: int = 1) -> str: """ Searches the research paper collection for a given query. Args: query_text (str): The text to search for. n_results (int): The number of results to return. Returns: str: The most relevant document found. """ # ChromaDB Cloud Client # This tool code is executed on the Letta server. It expects the ChromaDB # credentials to be passed as environment variables. api_key = os.getenv("CHROMA_API_KEY") tenant = os.getenv("CHROMA_TENANT") database = os.getenv("CHROMA_DATABASE")
if not all([api_key, tenant, database]): # If run locally without the env vars, this will fail early. # When run by the agent, these will be provided by the tool execution environment. raise ValueError("CHROMA_API_KEY, CHROMA_TENANT, and CHROMA_DATABASE must be set as environment variables.")
client = chromadb.CloudClient( tenant=tenant, database=database, api_key=api_key )
collection = client.get_or_create_collection("rag_collection")
try: results = collection.query( query_texts=[query_text], n_results=n_results )
document = results['documents'][0][0] return document except Exception as e: return f"Tool failed with error: {e}"This function, search_research_papers, takes a query, connects to our database, retrieves the top three most relevant documents, and returns them as a single string.
Step 5: Configure a “Smart” Research Agent
Section titled “Step 5: Configure a “Smart” Research Agent”Next, we’ll create a new, more advanced agent. This agent will have a specific persona that instructs it on how to behave and, most importantly, it will be equipped with our new search tool.
Create a file named create_agentic_agent.py:
import osfrom letta_client import Lettafrom dotenv import load_dotenvfrom tools import search_research_papers
load_dotenv()
# Initialize the Letta clientclient = Letta(token=os.getenv("LETTA_API_KEY"))
# Create a tool from our Python functionsearch_tool = client.tools.create_from_function(func=search_research_papers)
# Define the agent's personapersona = """You are a world-class research assistant. Your goal is to answer questions accurately by searching through a database of research papers. When a user asks a question, first use the `search_research_papers` tool to find relevant information. Then, answer the user's question based on the information returned by the tool."""
# Create the agent with the tool attachedagent = client.agents.create( name="Agentic RAG Assistant", description="A smart agent that can search a vector database to answer questions.", memory_blocks=[ { "label": "persona", "value": persona } ], tools=[search_tool.name])
print(f"Agent '{agent.name}' created with ID: {agent.id}")Run this script to create the agent:
python create_agentic_agent.pyConfigure Tool Dependencies and Environment Variables
Section titled “Configure Tool Dependencies and Environment Variables”For the tool to work within Letta’s environment, we need to configure its dependencies and environment variables through the Letta dashboard.
-
Find your agent
Navigate to your Letta dashboard and find the “Agentic RAG Assistant” agent you just created.
-
Access the ADE
Click on your agent to open the Agent Development Environment (ADE).
-
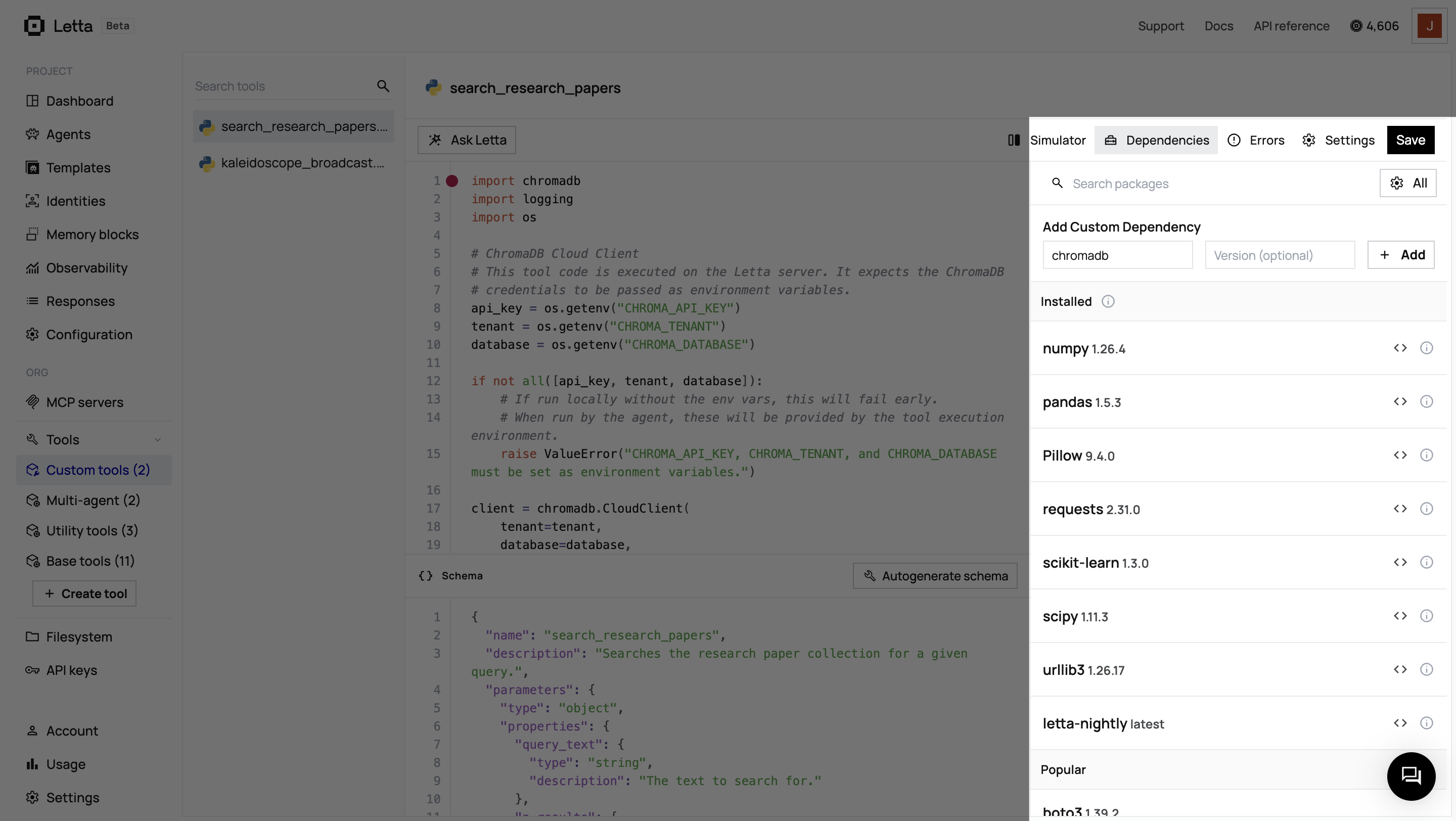
Configure Dependencies
- In the ADE, select Tools from the sidebar
- Find and click on the
search_research_paperstool - Click on the Dependencies tab
- Add
chromadbas a dependency
-
Configure Environment Variables
- In the same tool configuration, navigate to Simulator > Environment
- Add the following environment variables with their corresponding values from your
.envfile:CHROMA_API_KEYCHROMA_TENANTCHROMA_DATABASE
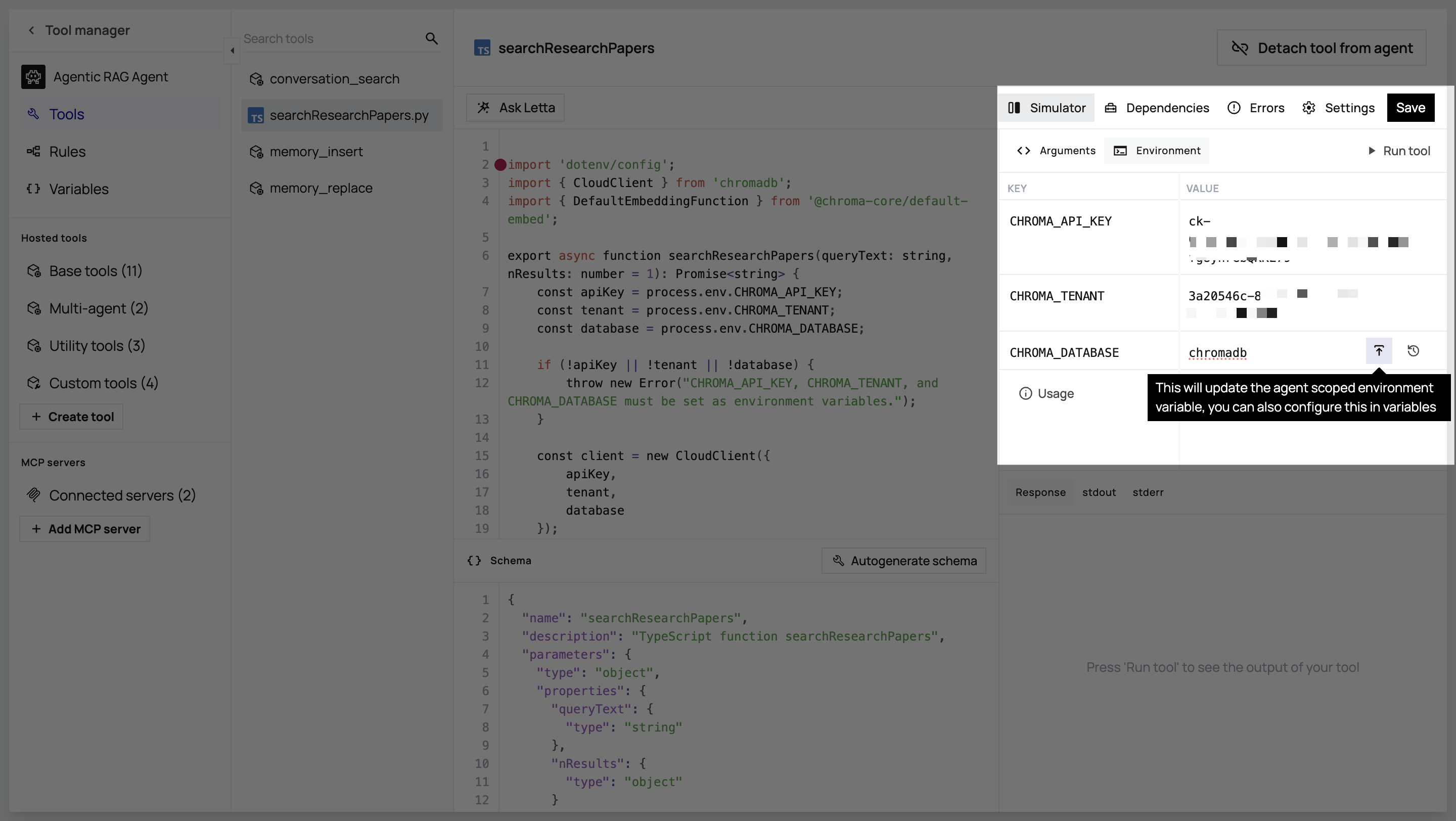
Now, when the agent calls this tool, Letta’s execution environment will know to install chromadb and will have access to the necessary credentials to connect to your database.
Step 6: Let the Agent Lead the Conversation
Section titled “Step 6: Let the Agent Lead the Conversation”With the agentic setup, our client-side code becomes incredibly simple. We no longer need to worry about retrieving context; we just send the user’s raw question to the agent and let it handle the rest.
Create the agentic_rag.py script:
import osfrom letta_client import Lettafrom dotenv import load_dotenv
load_dotenv()
# Initialize clientletta_client = Letta(token=os.getenv("LETTA_API_KEY"))
AGENT_ID = "your-agentic-agent-id" # Replace with your new agent ID
def main(): while True: user_query = input("Ask a question about the research papers: ") if user_query.lower() in ['exit', 'quit']: break
response = letta_client.agents.messages.create( agent_id=AGENT_ID, messages=[{"role": "user", "content": user_query}] )
for message in response.messages: if message.message_type == 'assistant_message': print(f"Agent: {message.content}")
if __name__ == "__main__": main()When you run this script, the agent receives the question, understands from its persona that it needs to search for information, calls the search_research_papers tool, gets the context, and then formulates an answer. All the RAG logic is handled by the agent, not your application.
Which Approach Is Right for You?
Section titled “Which Approach Is Right for You?”We’ve explored two powerful methods for connecting a custom RAG pipeline to a Letta agent. The best choice depends on your specific needs.
-
Use Standard RAG when…
- You want to maintain complete, fine-grained control over the retrieval process.
- Your retrieval logic is complex and better handled by your application code.
- You want to keep your agent as simple as possible and minimize its autonomy.
-
Use Agentic RAG when…
- You want to build a more autonomous agent that can handle complex, multi-step queries.
- You prefer simpler, cleaner client-side code.
- You want the agent to decide when and what to search for, leading to more dynamic conversations.
What’s Next?
Section titled “What’s Next?”Now that you’ve integrated a custom RAG pipeline, you can expand on this foundation. Here are a few ideas:
Integrate Other Vector Databases
Swap out ChromaDB for other providers like Weaviate, Pinecone, or a database you already have in production. The core logic remains the same: create a tool that queries your database and equip your agent with it.
Build More Complex Tools
Create tools that not only read from your database but also write new information to it. This would allow your agent to learn from its interactions and update its own knowledge base over time.
Add More Data Sources
Expand your RAG pipeline to include more documents, web pages, or other sources of information. The more comprehensive your data source, the more capable your agent will become.