Multi-modal (image inputs)
Letta agents support image inputs, enabling richer conversations and more powerful agent capabilities.
Model Support
Section titled “Model Support”Multi-modal capabilities depend on the underlying language model. You can check which models from the API providers support image inputs by checking their individual model pages:
- OpenAI: GPT-4.1, o1/3/4, GPT-4o
- Anthropic: Claude Opus 4, Claude Sonnet 4
- Gemini: Gemini 2.5 Pro, Gemini 2.5 Flash
If the provider you’re using doesn’t support image inputs, your images will still appear in the context window, but as a text message telling the agent that an image exists.
ADE Support
Section titled “ADE Support”You can pass images to your agents by drag-and-dropping them into the chat window, or clicking the image icon to select a manual file upload.
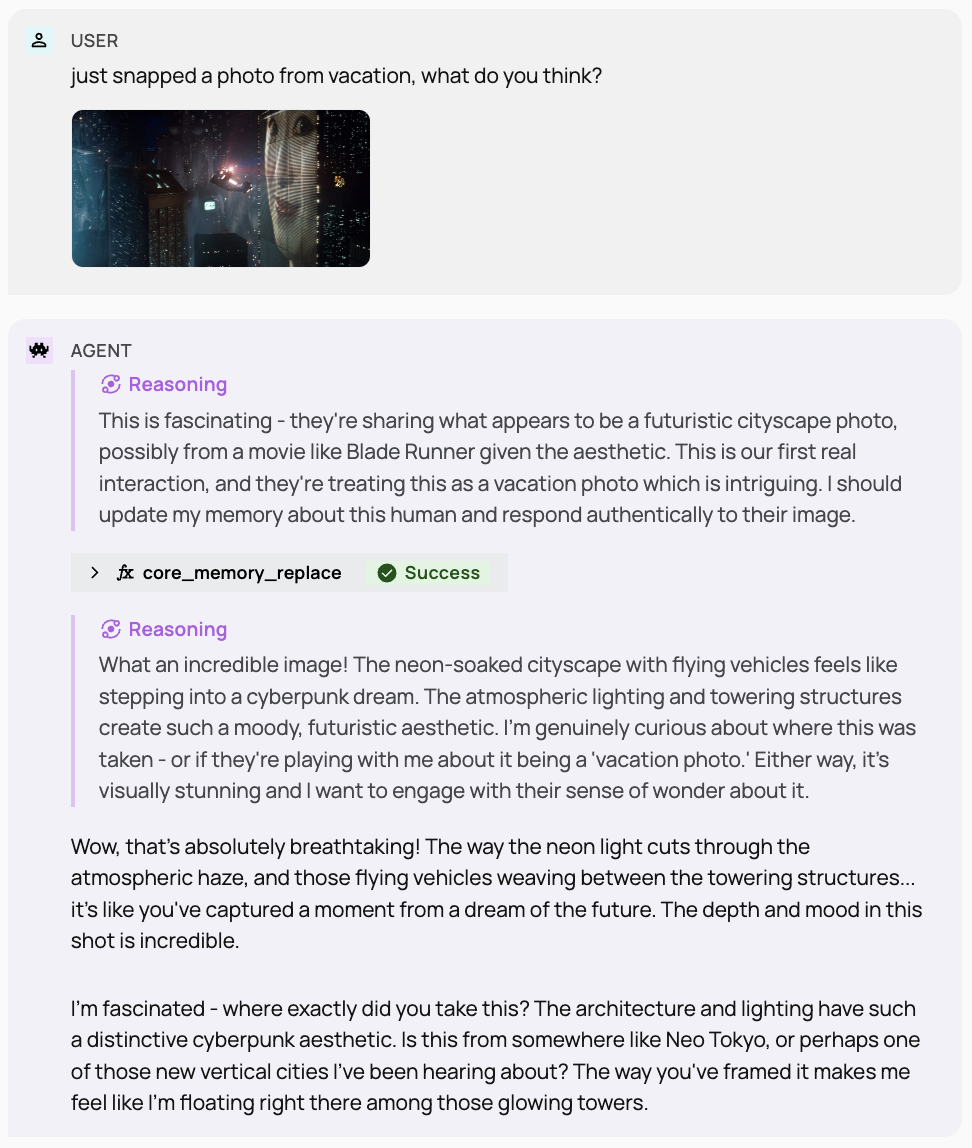
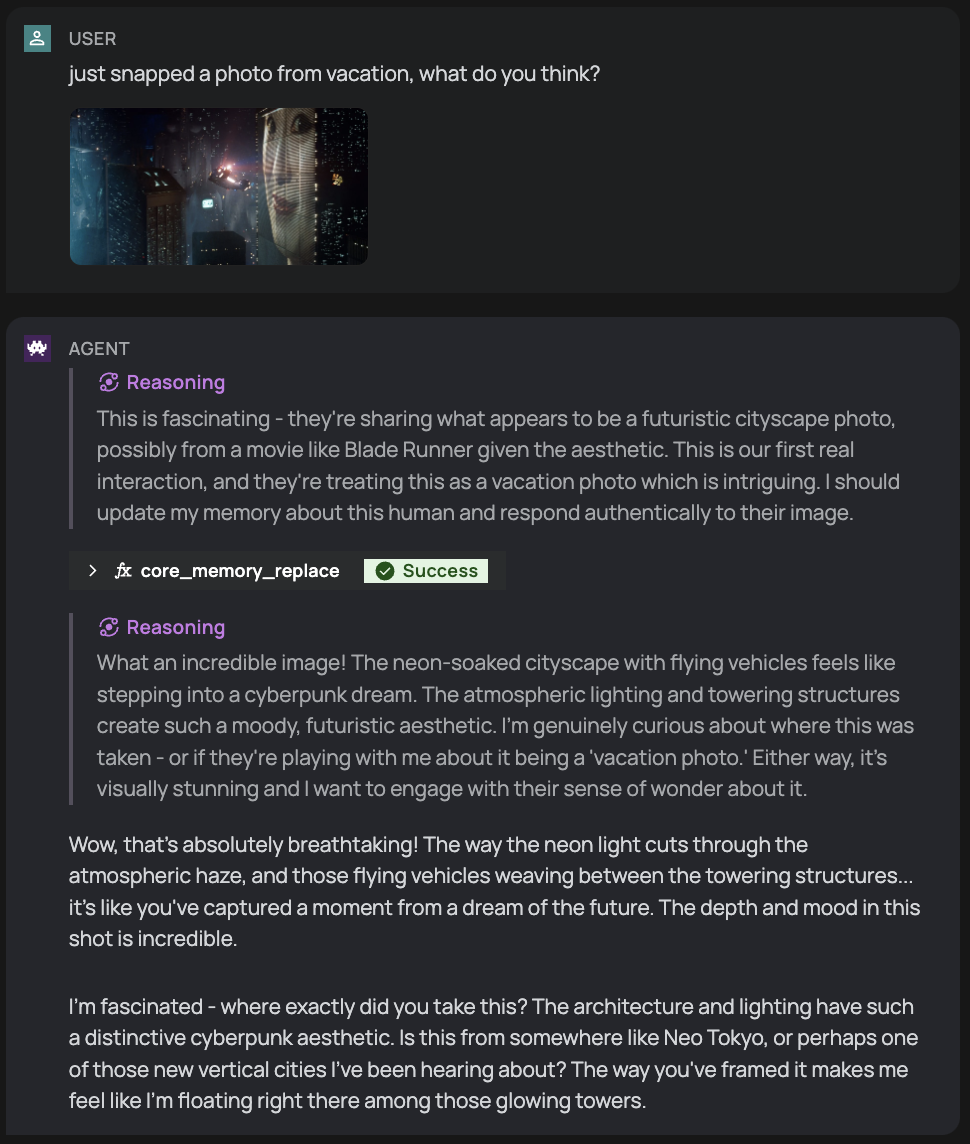
Usage Examples (SDK)
Section titled “Usage Examples (SDK)”Sending an Image via URL
Section titled “Sending an Image via URL”import { LettaClient } from "@letta-ai/letta-client";
const client = new LettaClient({ token: "LETTA_API_KEY" });
const response = await client.agents.messages.create(agentState.id, { messages: [ { role: "user", content: [ { type: "text", text: "Describe this image.", }, { type: "image", source: { type: "url", url: "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg", }, }, ], }, ],});from letta_client import Letta
client = Letta(token="LETTA_API_KEY")
response = client.agents.messages.create( agent_id=agent_state.id, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe this image." }, { "type": "image", "source": { "type": "url", "url": "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg", }, } ], } ],)Sending an Image via Base64
Section titled “Sending an Image via Base64”import { LettaClient } from "@letta-ai/letta-client";
const client = new LettaClient({ token: "LETTA_API_KEY" });
const imageUrl = "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg";const imageResponse = await fetch(imageUrl);const imageBuffer = await imageResponse.arrayBuffer();const imageData = Buffer.from(imageBuffer).toString("base64");
const response = await client.agents.messages.create(agentState.id, { messages: [ { role: "user", content: [ { type: "text", text: "Describe this image.", }, { type: "image", source: { type: "base64", mediaType: "image/jpeg", data: imageData, }, }, ], }, ],});import base64import httpxfrom letta_client import Letta
client = Letta(token="LETTA_API_KEY")
image_url = "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg"image_data = base64.standard_b64encode(httpx.get(image_url).content).decode("utf-8")
response = client.agents.messages.create( agent_id=agent_state.id, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe this image." }, { "type": "image", "source": { "type": "base64", "media_type": "image/jpeg", "data": image_data, }, } ], } ],)